Machine Learning Foundations Homework 2
Website of Machine Learning Foundations by Hsuan-Tien Lin: https://www.csie.ntu.edu.tw/~htlin/mooc/.
Question 1
Question 1-2 are about noisy targets.
Consider the bin model for a hypothesis that makes an error with probability in approximating a deterministic target function (both and outputs . If we use the same to approximate a noisy version of given by
What is the probability of error that makes in approximating the noisy target ?
Ans:
Explanation
A noisy version of means will have opposite sign as . The probability of being noisy, i.e., , is and will make an error in this case if and only if , which has probability , multiply these two probablity to get . On the other hand, if is not noisy, i.e., , then will make an error if and only if , so the probability is . Adding these two probabilities together we will obtain the answer.
Question 2
Following Question 1, with what value of will the performance of be independent of ?
(i) 1
(ii) one of the other choices
(iii) 0.5
(iv) 0
(v) 0 or 1
Ans: (iii) 0.5
Explanation
To make irrelevant to , we must eliminate . will work.
Question 3
Question 3-5 are about generalization error, and getting the feel of the bounds numerically. Please use the simple upper bound on the growth function , assuming that and .
For an with , if you want % confidence that your generalization error is at most 0.05, what is the closest numerical approximation of the sample size that VC generalization bound predicts?
(i) 500,000
(ii) 480,000
(iii) 420,000
(iv) 440,000
(v) 460,000
Ans: (v) 460,000
Recall vc bound is .
import numpy as np
def vc_bound(N, d_vc, epsilon):
"""
VC bound for "bad event", i.e., the probability of |E_in - E_out| > epsilon.
Args:
N: int, sample size
d_vc: int, vc dimension of the given hypothesis set H
epsilon: double, error
Returns:
VC bound
"""
return 4 * (2 * N) ** d_vc * np.exp(-1/8 * epsilon ** 2 * N)
N = 10_000
d_vc = 10
epsilon = 0.05
delta = 0.05 # delta = 1 - confidence
while vc_bound(N, d_vc, epsilon) > delta:
N += 10_000
Output:
N
460000
Question 4
There are a number of bounds on the generalization error , all holding with probability at least . Fix and and plot these bounds as a function of . Which bound is the tightest (smallest) for very large , say ? Note that Devroye and Parrondo & Van den Broek are implicit bounds in .
(i) Original VC bound:
(ii) Rademacher Penalty Bound:
(iii) Parrondo and Van den Broek:
(iv) Devroye:
(v) Variant VC bound:
def origin_vc_bound(N, delta, d_vc):
return np.sqrt(8/N * np.log((4. * (2 * N) ** d_vc)/delta))
def rademacher_penalty_bound(N, delta, d_vc):
return np.sqrt(2/N * np.log(2.*N * N ** d_vc)) + np.sqrt(2/N * np.log(1./delta)) + 1/N
def parrondo_and_Van(N, delta, d_vc):
def Delta(N, delta, d_vc):
return 4/N**2 + 4/N * (np.log(6/delta) + d_vc * np.log(2 * N))
# print("Delta=", Delta(N, delta, d_vc))
return 1/N + 1/2 * np.sqrt(Delta(N, delta, d_vc))
def devroye(N, delta, d_vc):
def Delta(N, delta, d_vc):
return 4/N**2 + (1 - 2/N) * 2/N * (np.log(4/delta) + 2 * d_vc * np.log(N))
# print("Delta=", Delta(N, delta, d_vc))
return (2/N + np.sqrt(Delta(N, delta, d_vc))) / (2 * (1 - 2/N))
def variant_vc_bound(N, delta, d_vc):
return np.sqrt(16/N * np.log(2. * N ** d_vc / np.sqrt(delta)))
import matplotlib.pyplot as plt
d_vc = 50
delta = 0.05
fig, ax = plt.subplots(1, 1, figsize=(8, 6))
Ns = range(1_000, 20_000, 1_000)
ax.plot(Ns, [origin_vc_bound(N, delta, d_vc) for N in Ns], label='Origin BC bound')
ax.plot(Ns, [rademacher_penalty_bound(N, delta, d_vc) for N in Ns], label='Rademacher Penalty Bound')
ax.plot(Ns, [parrondo_and_Van(N, delta, d_vc) for N in Ns], label='Parrondo and Van den Broek Bound')
ax.plot(Ns, [devroye(N, delta, d_vc) for N in Ns], label='Devroye Bound')
ax.plot(Ns, [variant_vc_bound(N, delta, d_vc) for N in Ns], label='Variant VC Bound')
ax.set_title("Different Bounds on the Generalization error")
ax.set_xlabel("N")
ax.set_ylabel("bounds epsilon")
ax.vlines(x=10000, ymin=0, ymax=2)
ax.legend();
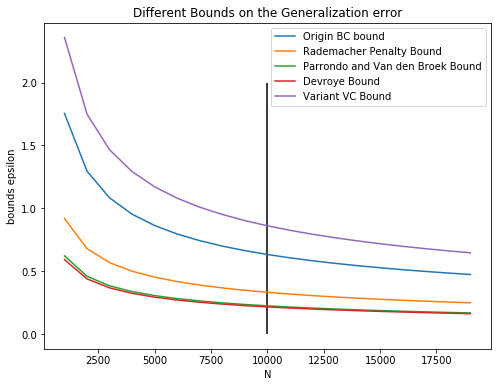
Output:
devroye(10000, 0.05, 50)
0.21522804980824667
parrondo_and_Van(10000, 0.05, 50)
0.2236982936807856
As can be seen from the picture, Devroye bound is the tightest (although it is very close to Parrondo and Van den Broek bound).
Question 5
Continuing from Question 4, for small , say , which bound is the tightest (smallest)?
d_vc = 50
delta = 0.05
fig, ax = plt.subplots(1, 1, figsize=(8, 6))
Ns = range(3, 10, 1)
ax.plot(Ns, [origin_vc_bound(N, delta, d_vc) for N in Ns], label='Origin BC bound')
ax.plot(Ns, [rademacher_penalty_bound(N, delta, d_vc) for N in Ns], label='Rademacher Penalty Bound')
ax.plot(Ns, [parrondo_and_Van(N, delta, d_vc) for N in Ns], label='Parrondo and Van den Broek Bound')
ax.plot(Ns, [devroye(N, delta, d_vc) for N in Ns], label='Devroye Bound')
ax.plot(Ns, [variant_vc_bound(N, delta, d_vc) for N in Ns], label='Variant VC Bound')
ax.set_title("Different Bounds on the Generalization error")
ax.set_xlabel("N")
ax.set_ylabel("bounds epsilon")
ax.legend();
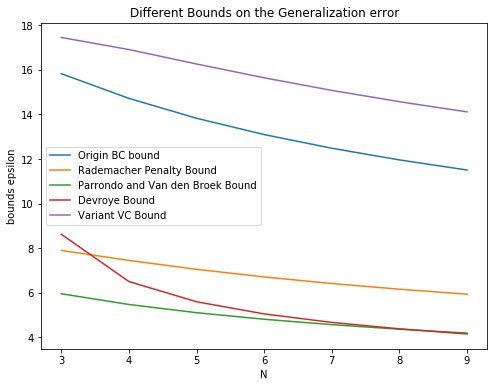
As can be seen from the picture, when is small, Parrondo and Van den Broek bound is the tightest.
Question 6
In Question 6-11, you are asked to play with the growth function or VC-dimension of some hypothesis sets.
What is the growth function of “positive-and-negative intervals on ”? The hypothesis set of “positive-and-negative intervals” contains the functions which are +1 within an interval and -1 elsewhere, as well as the functions which are -1 within an interval and +1 elsewhere. For instance, the hypothesis is a negative interval with -1 within and +1 elsewhere, and hence belongs to . The hypothesis contains two positive intervals in and and hence does not belong to .
Ans:
Explanation
First, we can choose interval ends from spots to form either positive or negative intervals. Note that cases of all ‘o’ or ‘x’ are included in and count exactly once: positive interval containing all points and negative interval containing all points.
However, there still exist replicates.
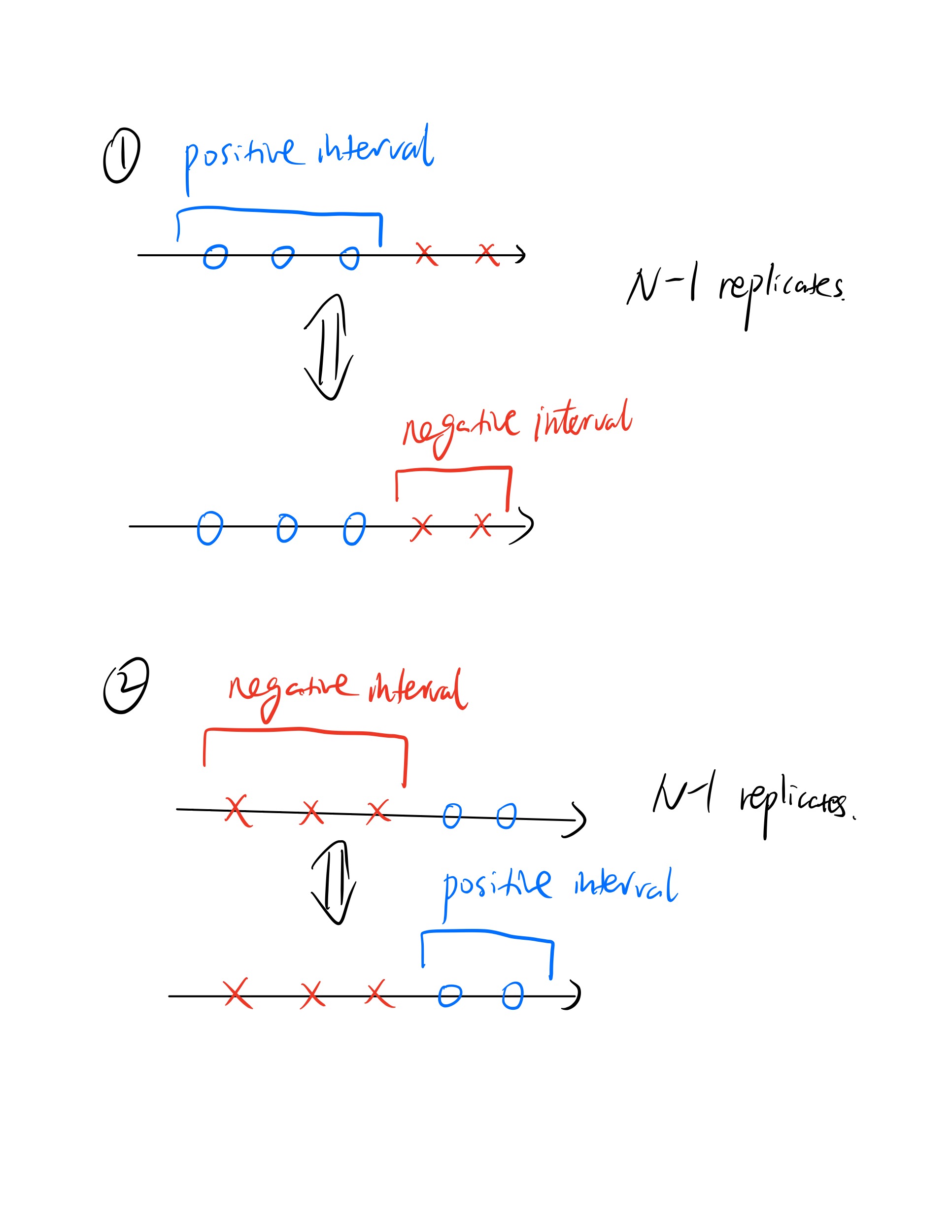
Hence, the result is .
Question 7
Continuing from the previous problem, what is the VC-dimension of the “positive-and-negative intervals on ”?
Ans: 3, which is the largest number of inputs that can be shattered.
Question 8
What is the growth function of “positive donuts in ”? The hypothesis set of “positive donuts” contains hypotheses formed by two concentric circles centered at the origin. In particular, each hypothesis is +1 within a “donut” region and -1 elsewhere. Without loss of generality, we assume .
Ans:
Explanation
If we think carefully, then we can recognize that this is similar to the positive interval case in : points corresponds to radiuses and we need to choose 2 radiuses from spots. Finally add the all ‘x’ case.
Question 9
Consider the “polynomial discriminant” hypothesis set of degree on , which is given by
What is the VC-Dimension of such an ?
Ans:
Explanation
is exactly a -D perceptrons since it’s a linear separator in dimensions, and we have learnt the VC dimension of -D perceptron is .
Question 10
Consider the “simplified decision trees” hypothesis set on , which is given by
That is, each hypothesis makes a prediction by first using the thresholds to locate to be within one of the hyper-rectangular regions, and looking up to decide whether the region should be +1 or -1. What is the VC-dimension of the “simplified decision trees” hypothesis set?
Ans:
Explanation
Consider a simple case: , then , , are all vectors in .
Since hypothesis is related to and , suppose is given. It divides the whole plane into 4 partitions. Suppose we have 4 points (like the image below), each of which is in one particular partition and we ask ourselves: how will classify them, ‘x’ or ‘o’?
Well, it depends on what looks like. If contains all 4 possible vectors: , then what will the first point be? Because the and components of the first point is less than and , respectively, its will be and IS IN ! So and will be , which means the first point will be classified as ‘o’.
Similarlly, all the other three points will be classified as ‘o’ since are all in our set . Now, we have obtained one dichotomy: all ‘o’s.
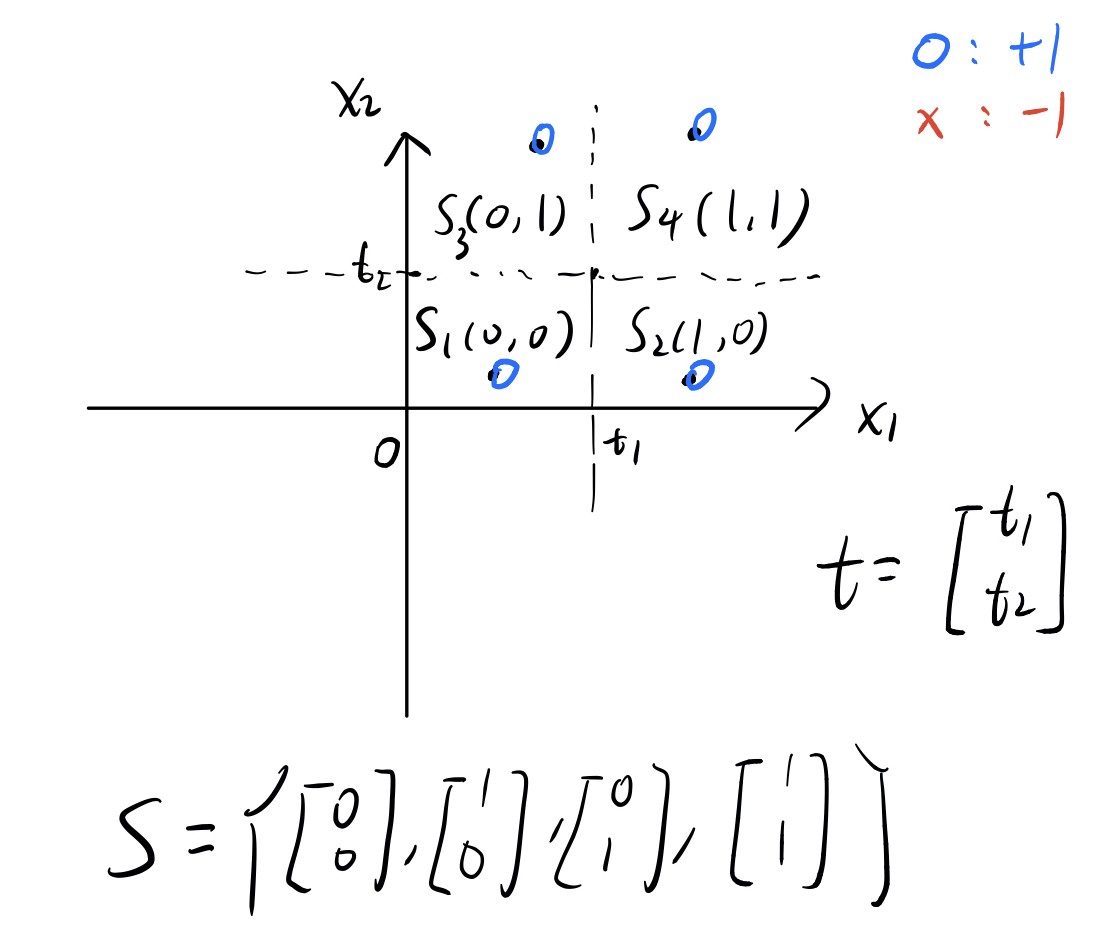
Well, how do we get other dichotomies? Let’s say change the third point to ‘x’ and leave the other three the same. In this case, we can simply take out of our , and the of the third point will not be in again, which means the point will be an ‘x’!
Proceeding in this manner, we can obtain all 16 possible dichotomies, which implies these 4 points are shattered by our hypothesis set.
What about 5 points? Well, then at least two of these points will be in the same partition and hence must have the same shape. So any 5 points cannot be shattered. The VC dimension of this hypothesis set is .
In the more general case, the above argument still applies and thus we can conclude the VC dimension of this hypothesis set is .
Question 11
Consider the “triangle waves” hypothesis set on , which is given by
Here is a number for some integer such that . For instance, is , and is .
What is the VC-Dimension of such an ?
Ans:
Explanation: A Pictorial Proof ^_^
You can try the code below and see the answer.
import matplotlib.pyplot as plt
from ipywidgets import interact, FloatSlider
import ipywidgets as widgets
from tqdm.notebook import tqdm
class DynamicWave(object):
def __init__(self, wave, pts):
self.wave = wave
self.pts = []
self.n = len(pts)
self.dychotomies = set()
dychotomy = ""
for pt in pts:
self.pts.append(pt)
pt.wave = self.wave
dychotomy += pt.get_shape()
self.dychotomies.add(dychotomy)
def dynamic(self, new_alpha, draw=True):
self.wave.change_alpha(new_alpha)
# After changing alpha, dynamically change the shape of points as well
dychotomy = ""
for pt in self.pts:
pt.shape_it()
dychotomy += pt.get_shape()
if dychotomy not in self.dychotomies:
self.dychotomies.add(dychotomy)
get_all_dychotomies = (len(self.dychotomies) == 2 ** self.n)
if draw:
# Redraw the picture
self.wave.ax.clear()
self.wave.draw()
for pt in self.pts:
pt.draw()
self.wave.ax.legend(loc="lower left")
self.wave.fig.show()
if not get_all_dychotomies:
print(f"Current have {len(self.dychotomies)} dychotomies: {self.dychotomies}")
if get_all_dychotomies:
print(f"We have get all 2^{self.n} dichotomies!")
print(f"{self.dychotomies}")
return get_all_dychotomies
class Wave(object):
def __init__(self, alpha, start, end, fig=None, ax=None):
self.alpha = alpha
self.fig = fig
self.ax = ax
self.start = start
self.end = end
def change_alpha(self, new_alpha):
self.alpha = new_alpha
def draw(self):
xs = np.linspace(self.start, self.end, 1000)
ys = [self.wave(x) for x in xs]
ax.plot(xs, ys)
ax.hlines(y=0, xmin=self.start, xmax=self.end) # Add x-axis
ax.vlines(x=0, ymin=-1.2, ymax=1.2) # Add y-axis
def wave(self, x):
return self.sign(abs((self.alpha * x) % 4 - 2) - 1)
@staticmethod
def sign(x):
return 1 if x > 0 else -1
class Point(object):
def __init__(self, wave, x):
self.wave = wave
self.x = x
self.shape = None
self.shape_it()
def shape_it(self):
if self.wave.wave(self.x) == 1:
self.shape = 'o'
else:
self.shape = 'x'
def get_shape(self):
return self.shape
def draw(self):
ax = self.wave.ax
if self.get_shape() == 'o':
ax.plot(self.x, 0, color='blue', marker='o', label="+1")
elif self.get_shape() == 'x':
ax.plot(self.x, 0, color='red', marker='x', label="-1")
else:
raise Exception("The shape has been changed to neither 'o' nor 'x', please check it!")
# use the notebook backend
%matplotlib notebook
"""
NOTE1: Using random points can speed up finding all dychotomies
Moreover, if we increase the range of the points, we can speed up too!
e.g. pts = [Point(w1, x) for x in 1e7*np.random.rand(5)]
NOTE2: Uniformly distributed points have hard time finding all dychotomies.
e.g. pts = [Point(w1, x) for x in np.linspace(0, 2, 4)]
After running a few numerical experiments, I guess it's even impossible
to find all dychotomies in this case. If you have any idea, please tell me
and we can discuss about it.
"""
fig, ax = plt.subplots(1, 1, figsize=(8, 4))
x_start = -8
x_end = 8
w1 = Wave(1, x_start, x_end, fig, ax)
pts1 = [Point(w1, x) for x in np.linspace(0, 8, 5)]
dw = DynamicWave(w1, pts1)
interact(dw.dynamic, new_alpha=FloatSlider(min=1e-5, max=1000, step=1e-7));
Try different alpha’s.
"""
Try different alpha's ^_^
"""
x_start = -8
x_end = 8
w2 = Wave(alpha=1, start=x_start, end=x_end)
pts2 = [Point(w2, x) for x in 1000*np.random.rand(12)]
dw2 = DynamicWave(w2, pts2)
get_all_dychotomies = False
# Set alpha from 0 to 1000, totally 10^7 different values
for alpha in tqdm(np.linspace(0, 1000, 1e7)):
get_all_dychotomies = dw2.dynamic(alpha, draw=False)
if get_all_dychotomies:
break
if get_all_dychotomies:
print("Cheers!")
else:
print("failed...")
Question 12
In Question 12-15, you are asked to verify some properties or bounds on the growth function and VC-dimension.
Which of the following is an upper bound of the growth function for ?
(i)
(ii)
(iii)
(iv)
(v) none of the other choices
Ans: (iv)
Explanation
(i): contains no part and is constant as grows, but our growth function typically tends to infinity as increases and hence cannot be an upper bound.
(ii): Consider the 1D perceptron. In this case is 2 and . Comparing to , we see cannot be an upper bound.
(iii): Growth function is non-decreasing and is less than for , so this can not be an upper bound.
(v): Every time we put one more point, we can, at most, double our dichotomies, so . Repeat times we see for every . Therefore, their minimum value is an upper bound for .
Question 13
Which of the following is not a possible growth function for some hypothesis set?
(i)
(ii)
(iii)
(iv)
Ans: (ii)
Explanation
If , then since , thus must be bounded by , which is false.
Question 14
For hypothesis sets with finite, positive VC dimensions , some of the following bounds are correct and some are not. Which among the correct ones is the tightest bound on the VC dimension of the intersection of the sets: ? (The VC dimension of an empty set or a singleton set is taken as zero)
(i)
(ii)
(iii)
(iv)
(v)
Ans: (iv)
Explanation
The VC dimension of the intersection cannot exceed each of the individual one’s. Moreover, if the intersection is empty, then the VC dimension is zero.
Question 15
For hypothesis sets with finite, positive VC dimensions , some of the following bounds are correct and some are not. Which among the correct ones is the tightest bound on the VC dimension of the union of the sets: ?
(i)
(ii)
(iii)
(iv)
(v)
Ans: (v)
Explanation
The VC dimension of the union is at least as large as each individual one’s, thus . Next, we show the other direction: .
Proof: We prove by induction on . First, suppose and let and . Notice that the number of dichotomies that can generate is at most the sum of the dichotomies generated by and since they may have some dichotomies in common. So we have the following inequalities
for all satisfying i.e., .
The above inequality implies that if we have more than input points, i.e. , then they cannot be shattered by our union set . Therefore, we can deduce that
Now suppose the result is correct for , we will prove it for . We have that
Question 16
For Question 16-20, you will play with the decision stump algorithm.
In class, we taught about the learning model of “positive and negative rays” (which is simply one-dimensional perceptron) for one-dimensional data. The model contains hypotheses of the form:
The model is frequently named the “decision stump” model and is one of the simplest learning models. As shown in class, for one-dimensional data, the VC dimension of the decision stump model is 2.
In fact, the decision stump model is one of the few models that we could easily minimize efficiently by enumerating all possible thresholds. In particular, for examples, there are at most dichotomies (see page 22 of class05 slides), and thus at most different values. We can then easily choose the dichotomy that leads to the lowest , where ties can be broken by randomly choosing among the lowest- ones. The chosen dichotomy stands for a combination of some “spot” (range of ) and , and commonly the median of the range is chosen as the that realizes the dichotomy.
In this problem, you are asked to implement such an algorithm and run your program on an artificial data set. First of all, start by generating a one-dimensional data by the procedure below:
(a) Generate by a uniform distribution in .
(b) Generate by plus noise, where and the noise flips the result with 20% probability.
For any decision stump with , express as a function of and .
Ans:
By Question 1, the probability of error that makes in approximating noisy target is . In this question, is 0.8, which is the probability that the result will not be flipped. We only need to figure out the probability .
Consider two cases and :
(i) For ,
(ii) For ,
We can combine the two cases into one equation like
Plugging and , we can obtain the result
Question 17
Generate a data set of size 20 by the procedure above and run the one-dimensional decision stump algorithm on the data set. Record and compute with the formula above. Repeat the experiment (including data generation, running the decision stump algorithm, and computing and ) 5,000 times. What is the average ? Choose the closest option.
(i) 0.05
(ii) 0.35
(iii) 0.25
(iv) 0.45
(v) 0.15
Generate Data Set
def generateXY(n):
"""
Generate a data set (x, y) with size n by
(a) Generate x by a uniform distribution in [-1, 1];
(b) Generate y by f(x) = sign(x) plus noise,
where the noise flips the result with 20%
probability.
Args:
n: int, size of data set to generate
Returns:
data: numpy array, n x 2, result data set
"""
x = np.random.uniform(low=-1, high=1, size=n)
y = noisy_vec(sign_vec(x))
data = np.c_[x, y]
return data
###### Some helper functions ######
def sign(x):
return 1 if x > 0 else -1
# Vectorized version of the above sign function
sign_vec = np.vectorize(sign)
def noisy(y):
random_num = np.random.rand()
if random_num < 0.2:
y = -y
return y
# Vectorized version of the above noisy function
noisy_vec = np.vectorize(noisy)
Implement Decision Stump Algorithm
def decision_stump(X, y):
"""
Decision stump algorithm. Choose the lowest Ein among all 2N possible cases.
Args:
X: numpy array(n, )
y: numpy array(n, )
Returns:
min_Ein: double
theta_best: double
s_best: int, +1 or -1
"""
n = X.shape[0]
sorted_idx = np.argsort(X)
X = X[sorted_idx]
y = y[sorted_idx] ### DO NOT forget to sort y as well!
min_Ein = np.inf
theta_best = None
s_best = None
for i in range(n - 1):
# Use the middle of two consecutive xs as theta
theta_median = (X[i] + X[i+1]) / 2
for s in (-1, 1):
Ein = E_in(X, y, s, theta_median)
if Ein < min_Ein:
min_Ein = Ein
theta_best = theta_median
s_best = s
# Test all 'x' or 'o' cases
for s in (-1, 1):
Ein = E_in(X, y, s, X[-1]) # Set theta to the largest x
if Ein < min_Ein:
min_Ein = Ein
theta_best = theta_median
s_best = s
return min_Ein, theta_best, s_best
###### Some helper functions ######
def E_in(X, y, s, theta):
return np.mean(h_vec(X, s, theta) != y)
def h(x, s, theta):
return s * sign(x - theta)
h_vec = np.vectorize(h)
def E_out(s, theta):
return 0.5 + 0.3 * s * (abs(theta) - 1)
E_in_lst = []
E_out_lst = []
for _ in tqdm(range(5000)):
data = generateXY(20)
X, y = data[:, 0], data[:, 1]
Ein, theta, s = decision_stump(X, y)
Eout = E_out(s, theta)
E_in_lst.append(Ein)
E_out_lst.append(Eout)
print(f"Average of Ein:{np.mean(E_in_lst)}")
Average of Ein:0.17065
Question 18
Continuing from the previous question, what is the average ?
print(f"Average of Eout:{np.mean(E_out_lst)}")
Average of Eout:0.25728720737019756
Question 19
Decision stumps can also work for multi-dimensional data. In particular, each decision stump now deals with a specific dimension , as shown below.
Implement the following decision stump algorithm for multi-dimensional data:
(a) for each dimension , find the best decision stump using the one-dimensional decision stump algorithm that you have just implemented.
(b) return the “best of best” decision stump in terms of . If there is a tie, please randomly choose among the lowest- ones.
The training data is at hw2_train.dat.
The testing data is at hw2_test.dat.
Run the algorithm on the . Report the of the optimal decision stump returned by your program. Choose the closest option.
(i) 0.25
(ii) 0.05
(iii) 0.35
(iv) 0.45
(v) 0.15
def multi_decision_stump(X, y):
"""
Choose the dimension with the lowest Ein to classify data.
Args:
X: numpy array (n, d)
y: numpy array (n, )
Returns:
min_Ein : double
theta_best: double
s_best : int, +1 or -1
dim_best : int starts with 1, dimension with the lowest Ein
"""
n, d = X.shape
min_Ein = np.infty
theta_best = None
s_best = None
dim_best = None
for i in range(d):
X_i = X[:, i]
Ein, theta, s = decision_stump(X_i, y)
if Ein < min_Ein:
min_Ein = Ein
theta_best = theta
s_best = s
dim_best = i + 1
return min_Ein, theta_best, s_best, dim_best
import pandas as pd
# Load data
train_data = pd.read_csv('hw2_train.dat', sep='\s+', header=None)
test_data = pd.read_csv('hw2_test.dat', sep='\s+', header=None)
# Construct features and labels
y_train = train_data.iloc[:, -1].to_numpy() # The last column is label y
X_train = train_data.iloc[:, :-1].to_numpy() # Features are all previous columns
y_test = test_data.iloc[:, -1].to_numpy()
X_test = test_data.iloc[:, :-1].to_numpy()
min_Ein, theta_best, s_best, dim_best = multi_decision_stump(X_train, y_train)
print(f"Optimal Ein: {min_Ein}")
Optimal Ein: 0.25
As shown above, is 0.25.
Question 20
Use the returned decision stump to predict the label of each example within the . Report an estimate of by . Choose the closest option.
(i) 0.45
(ii) 0.35
(iii) 0.05
(iv) 0.15
(v) 0.25
def E_test(X_test, y_test, theta_best, s_best, dim_best):
# Use the best dimension to classify data
X_test_dim = X_test[:, dim_best-1]
Etest = E_in(X_test_dim, y_test, s_best, theta_best)
return Etest
E_test(X_test, y_test, theta_best, s_best, dim_best)
Output:
0.355
As shown above, is about 0.35.